
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 경로 계획 알고리즘
- 청첩장 모임
- ssh
- Go-lang
- docker
- AWS 비용 절감
- 회고
- 디자인 패턴
- github
- AWS
- study
- 커머스
- 신혼 여행
- Playwright
- 실용주의 프로그래머
- 지표
- Rust
- 티스토리챌린지
- leetcode
- MAPF
- 논문 정리
- 구조 패턴
- 14일 공부
- terraform
- amazon ecs
- PostgreSQL
- 오블완
- 생성 패턴
- Til
- DevOps
- Today
- Total
밤 늦게까지 여는 카페
[AWS RDS] Performance Insights 실전 가이드: DB 부하 분석 본문
안녕하세요. 오늘은 AWS RDS 부하 분석에 필수 도구인 Performance Insights에 대해서 공부한 내용을 정리하려고 합니다.
Performance Insights가 무엇인지, 어떻게 활용할 수 있는지 정리해봤는데 도움이 되었으면 좋겠네요!
TL-DR
- AAS 추이를 주기적으로 확인해서 이상 신호를 포착하면
- 튜플 returned/fetched, IO, 네트워크 등 다른 지표를 활용해서 근본 원인 분석
- 인덱스 추가, 쿼리 최적화, 인스턴스 유형 변경 등의 대응 방안 검토
1. Performance Insights가 뭐에요?
AWS RDS에서 제공하는 Performance Insights는 DB 병목 현상을 신속하게 파악할 수 있도록 도와주는 모니터링 도구입니다.
특히 DB Load를 시각화 해주는 것이 아주 유용합니다!
- 서비스가 어떤 쿼리를 사용하는지 모르더라도 그래프가 중간에 치솟으면 문제가 있구나 알겠더라고요

그런데 보여주는 지표들이 워낙 많다보니 이걸 어떻게 해석해야 할지 난감할 때가 많았습니다.
- 문제가 있다는 것만 알겠고, 정확히 무엇이 문제이고 어떻게 해결해야 하는지를 알아내기까지 시간이 소요됩니다.
CPU 사용률, 여유 메모리와 같이 직관적인 지표들이 있는 반면

Average Active Session(AAS), IO 캐시 대 디스크 읽기, 튜플: DML, 튜플: 읽기와 같이 생소한 지표들도 있었습니다.



Performance Insights를 처음 사용했을 때는 지표에 대한 큰 이해 없이 AAS 별 로드가 큰 SQL 쿼리들부터 최적화를 진행했습니다.
하지만 서비스가 성장할수록 쿼리는 복잡해지고 최적화 방법도 달라집니다.
조금이라도 더 빠르게 올바른 최적화 방안을 찾기 위해서는 각 지표들이 의미하는 바를 이해해야겠더라고요...!
2. 지표 이해하기
2.1. Average Active Session, AAS
RDS performance insights 사용해보셨다면 AAS라는 지표를 많이 보셨을 겁니다.
평균 활성 세션(AAS)로 현재 처리 중/처리되어야 하는 요청 수를 뜻합니다.
시작되지 않은 요청 + 진행 중인 요청의 개수로 값이 너무 크면 지연이 발생하고 있는 것입니다.
DB 인스턴스의 vCPU 이하로 유지되면 대부분의 요청이 지연 없이 처리된다는 것을 뜻합니다.
- m5.large의 경우 vCPU가 2이므로 AAS가 2이하로 유지되는 것이 좋습니다.

참고: https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/USER_PerfInsights.Overview.MaxCPU.html
그렇다고 AAS가 vCPU보다 높다고 해서 항상 부하가 발생한 것은 아닙니다.
서버 동작이 느려진 것 같다고 체감될 시 문제가 발생한 쿼리를 분석하는 것이 좋습니다!
AAS가 vCPU보다 높고 부하가 발생하고 있다면 원인이 무엇일까요?
다양한 원인으로 인해서 문제가 발생할 수 있습니다...
- 테이블에 index가 없어서 비효율적으로 데이터를 조회하고 있었거나
- DB의 메모리가 부족하여 디스크 읽기가 빈번하게 발생해서
- 등등
다른 지표들을 살펴보면서 원인 분석이 필요합니다!
2.2. 튜플: 읽기
테이블의 index가 잘못 설정되어 있거나 WHERE 절, JOIN 절이 잘못되어 있을 때
다음과 같이 returned 대비 fetched 지표가 낮은 값을 보여줍니다.
- 첨부한 그림은 사실 정상적인 상태입니다. 위의 문제가 발생했을 때는 fetched가 더 낮은 값을 보입니다.

지표를 통해서 문제 발생을 식별했다면 어떤 쿼리가 범인인지 알아봐야겠죠?
아쉽게도 PostgreSQL은 쿼리 별로 tup_returned, tup_fetched를 추적하는 기능이 없습니다.
그나마 EXPLAIN 명령어를 이용해서 실행된 쿼리의 tup_returned, tup_fetched를 계산할 수는 있습니다.
다음과 같이 EXPLAIN 명령어를 쿼리와 같이 사용하면
EXPLAIN ANALYZE SELECT * FROM orders WHERE time > 90;
- (customer_id VARCHAR(32) PRIMARY KEY, product_info VARCHAR(100), time INTEGER)
- 다음 쿼리를 이용해서 랜덤하게 row를 10000개 생성했습니다.
- INSERT INTO orders2 (customer_id, product_info, time)
SELECT
md5(i::text), -- 32자리 랜덤 문자열(고유 customer_id)
'product_' || (1 + (random()*100)::int), -- product_info에 임의의 값
random()*100::int
FROM generate_series(1, 10000) AS s(i);
- INSERT INTO orders2 (customer_id, product_info, time)
결과가 출력됩니다.
QUERY PLAN
---------------------------------------------------------------------------------------------------------
Seq Scan on orders (cost=0.00..219.00 rows=1002 width=47) (actual time=0.005..0.584 rows=976 loops=1)
Filter: ("time" > 90)
Rows Removed by Filter: 9024
Planning:
Buffers: shared hit=24
Planning Time: 0.098 ms
Execution Time: 0.616 ms
(8 rows)
위의 결과에서 actual 부분의 rows=976이 tup_fetched
actual rows=976+ Rows Removed by Filter=9024: 10000이 tup_returned라고 할 수 있습니다.
2.3. IO, 네트워크 처리량, 연결 수 - DB 인스턴스 유형 변경
제 경우에는 데이터를 Redis 혹은 메모리에 캐싱해서 DB에 과도한 데이터가 전달되는 것을 막았기 때문에
이 지표들과 직접적으로 연관된 문제가 발생하는 것이 극히 드물었습니다.
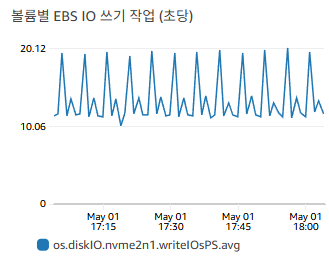


그래도 문제는 발생할 수 있으니
주로 쿼리 최적화보다는 DB 인스턴스 유형을 바꾸는 것으로 조치할 수 있습니다.
IO, 네트워크 처리량은 DB 인스턴스의 EBS 유형으로 인해 한계가 결정되며
=> 스토리지 유형을 변경하는(딸깍) 것으로 조치할 수 있습니다.
연결 수는 DB 인스턴스의 메모리 크기로 인해서 한계가 결정됩니다.
=> DB 인스턴스 유형을 변경하는(딸깍) 것으로 조치할 수 있습니다.
대응 방법은 간단하지만 비용과 직결되니 문제 해결에 필요한 수준을 정확히 파악하는 것이 중요합니다!
- 참고: https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/ebs-optimized.html
- 참고: https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/UserGuide/Concepts.DBInstanceClass.Summary.html#hardware-specifications.mem-opt-inst-classes
- 참고: https://docs.aws.amazon.com/ko_kr/AmazonRDS/latest/UserGuide/CHAP_Limits.html#RDS_Limits.MaxConnections
3. Performance Insights 단점은 없을까요?
3.1. 성능
AWS RDS Performance Insights FAQ에 따르면, Performance Insights를 사용했을 때 약간의 DB 성능 부하가 생길 수 있다고 합니다.
하지만 구체적으로 메모리 몇GB, CPU 몇 %가 소요되는지 알기 위해서는 서비스 워크로드로 직접 테스트 해보는 것을 권장합니다.
2018년에 우아한형제들 기술 블로그에 작성된 내용을 참고하면 메모리는 1.1GB, CPU는 8~10% 정도 더 소요된다고 합니다.
- 메모리 사용량은 performance_schema 옵션의 메모리 사용량으로 추정하셨습니다.
- CPU 사용량은 실제 워크로드로 테스트한 것으로 추정됩니다.
- 참고: https://techblog.woowahan.com/2593/
3.2. 비용
지표를 일주일만 보관해도 괜찮다면 프리 티어로 사용할 수 있습니다.
하지만 지표를 일주일 이상 보존하기 위해서는 추가적인 비용이 발생하게 됩니다.
- 지표는 최대 24개월까지 보존 가능합니다.
지표를 N개월 보존하는데 필요한 비용 계산식
- 1.7561 + 0.0739*(N-1)달러를 1 vCPU
- 참고: https://aws.amazon.com/rds/performance-insights/pricing
예시)
사용하고 있는 DB 인스턴스가 db.t4g.large이고 해당 인스턴스의 지표를 3개월 보존하고 싶다면
( 1.7561 + 0.0739*(3-1) ) * 2 = 3.81 달러를 월마다 지불해야 합니다.
db.t4g.micro부터 db.t4g.large까지는 vCPU를 2만큼 사용하고 있어서
micro, small 유형을 사용하고 있는 경우에는 비용이 부담스럽게 느껴질 수 있습니다.
'aws' 카테고리의 다른 글
| [AWS IoT Core] Cloudwatch 대비 60% 절감! Rule Engine+Athena로 데이터 수신 시각 추적하기 (0) | 2025.04.19 |
|---|---|
| [AWS IoT Core] Basic Ingest - 비싼 메시지 전송 비용 절약하는 방법 (0) | 2025.04.15 |
| [Amazon ECS] 혹시 컨테이너 이미지의 태그를 덮어 쓰시나요? 서비스들 재실행하십쇼... (0) | 2025.04.12 |
| [AWS 비용 절감] crontab을 이용해서 주말에는 서버 자동으로 내리기 (4) | 2025.02.16 |
| [2025.02.06] Amazon S3 Glacier Deep Archive 복구 경험 (1) | 2025.02.09 |


