
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 실용주의 프로그래머
- 디자인 패턴
- AWS
- 논문 정리
- 도커 주의사항
- DevOps
- 14일 공부
- 구조 패턴
- 생성 패턴
- 오블완
- 지표
- Rust
- github
- Til
- MAPF
- Monthly Checklist
- ssh
- Playwright
- 경로 계획 알고리즘
- 청첩장 모임
- PostgreSQL
- AWS 비용 절감
- 티스토리챌린지
- docker
- study
- leetcode
- Go-lang
- 신혼 여행
- terraform
- amazon ecs
- Today
- Total
밤 늦게까지 여는 카페
Lifelong Multi-Agent Path Finding in Large-Scale Warehouses - RHCR 원조가 여기라던데! 본문
Lifelong Multi-Agent Path Finding in Large-Scale Warehouses - RHCR 원조가 여기라던데!
Jㅐ둥이 2023. 8. 5. 23:12안녕하세요. 오늘은 Lifelong MAPF 문제를 Windowed 기반의 접근법으로 해결하는 방법을 연구한 Lifelong Multi-Agent Path Finding in Large-Scale Warehouse 논문을 공부하려고 합니다.
- LI, Jiaoyang, et al. Lifelong multi-agent path finding in large-scale warehouses. In: Proceedings of the AAAI Conference on Artificial Intelligence. 2021. p. 11272-11281.
물류센터 환경에서 가장 좋은 MAPF 모델은 뭘까요? 에서 사용되었던 Rolling Horizon Collision Resolution(RHCR)이 바로 이 논문에서 제안된 방법인데요.
간단하게 RHCR을 적용해도 괜찮은 이유를 생각하자면 1) 계속해서 경로를 재계획한다는 점, 2) 작업이 없어서 멈춰있는 로봇으로 인한 데드락도 없다 정도인데요.
논문에서는 어떻게 풀었는지 같이 공부해볼까요?
1. Introduction
RHCR을 자세히 살펴보기 전에 Lifelong MAPF 문제를 해결하려고 했던 선행 연구들을 살펴볼까요?
선행 연구들은 크게 다음 3가지 부류로 나눌 수 있습니다.
- Lifelong MAPF 문제 전체를 Offline MAPF 문제로 해결하는 방법
- Nguyen, V.; Obermeier, P.; Son, T. C.; Schaub, T.; and Yeoh, W. 2017. Generalized Target Assignment and Path Finding Using Answer Set Programming. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 1216–1223.
- Lifelong MAPF 문제를 MAPF의 시퀀스로 분해하고, 분해된 MAPF 문제를 매 timestep 마다 해결하는 방법
- Wan, Q.; Gu, C.; Sun, S.; Chen, M.; Huang, H.; and Jia, X. 2018. Lifelong Multi-Agent Path Finding in a Dynamic Environment. In Proceedings of the International Conference on Control, Automation, Robotics and Vision (ICARCV), 875–882.
- Svancara, J.; Vlk, M.; Stern, R.; Atzmon, D.; and Bart´ak, R. 2019. Online Multi-Agent Pathfinding. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 7732–7739.
- 2와 유사하지만 새로운 목적지로 가는 agent들의 경로만 계획하는 방법
아쉽게도 1, 2, 3 방법들 모두 현실 세계에서 적용하기에는 실행 시간이 너무 오래 걸리거나 만족시키기 어려운 가정이 필요합니다.
논문에서 제안하는 RHCR은 어떻게 이 문제점들을 해결했을까요?
2. 논문에서 제안한 방법
RHCR은 1) Lifelong MAPF 문제를 Windowed MAPF의 시퀀스로 분해하고, 2) 제한된 timestep 내의 collision만 해소하는 프레임워크고, 이를 통해서 효율성과 알고리즘의 실시간성을 얻을 수 있습니다.
RHCR 프레임워크를 적용한다는 것은 collision based search에서 주어진 window size w까지만 collision을 해소하고, 그 이후의 timestep에서는 collision 검사 없이 최단 경로를 계획합니다.
사실 저는 여기서 끝일줄 알았는데 원조는 달랐습니다. 바로 window size w에 대한 고찰이었는데요.
window size를 어떻게 설정하느냐에 따라서 효율이 달라지게 됩니다. 어려운 점은 window size가 크다고 해서 무조건 효율이 올라가는 것도 아니고, window size가 너무 작으면 deadlock이 발생할 수 있습니다.
논문에서는 Potential Function과 threshold p를 이용하여 적절한 window size를 찾는 방법을 제안합니다.
Potential Function은 계획된 경로가 진전이 있는지 판단해주는 heuristic 함수입니다.
논문에서는 식1을 Potential Function으로 삼았습니다.
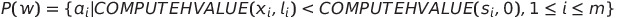
P(w)는 현재 위치로부터 현재 목적지까지의 거리(다른 로봇과의 충돌을 고려하지 않은 거리)가 초기 위치로부터 첫번째 목적지까지의 거리보다 짧은 로봇들의 수 입니다. w를 초기값부터 시작해서 P(w)가 p보다 같거나 커질 때까지 w를 증가시키면서 w를 찾는 것입니다.
3. 실험
논문에서는 식1의 Potential Function과 threshold p=1로 설정한채로 Amazon EC2 m4.xlarge 인스턴스를 이용하여 각 실험마다 5000번의 시뮬레이션을 통해서 성능을 측정했습니다.
그리고 시뮬레이션을 진행한 환경은 다음과 같습니다.
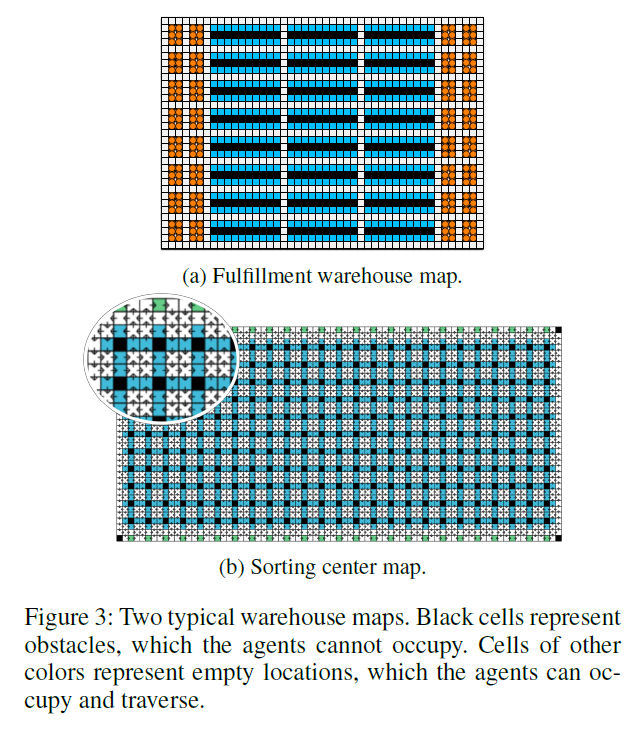
1. Fulfillment warehouse map 실험
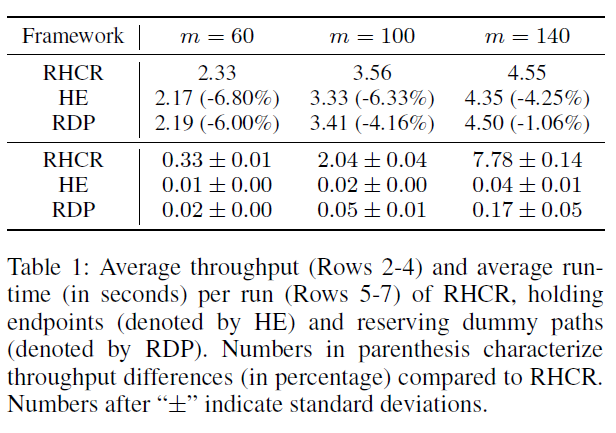
Fulfillment warehouse map에서는 PBS를 이용해서 RHCR, Holding Endpoints(HE), Reserving Dummp Path(RDP) 간의 성능 차이를 비교했습니다.
성능은 RHCR > RDP > HE 순으로 좋았습니다. 이는 HE와 RDP가 불필요한 collision을 고려하여 더 긴 경로를 계획하기 때문입니다.
반면에 실행시간은 RHCR이 가장 오래 걸렸습니다. HE와 RDP는 목적지에 도착한 로봇들을 대상으로만 경로를 재계획하지만 RDP는 주기적으로 모든 로봇에 대해서 경로를 재계획하기 때문입니다. 하지만 HE와 RDP는 매 timestep마다 경로를 재계획해야 하기 때문에 실제 상황에 적용하기에는 무리가 있습니다.
2. Sorting center map 실험
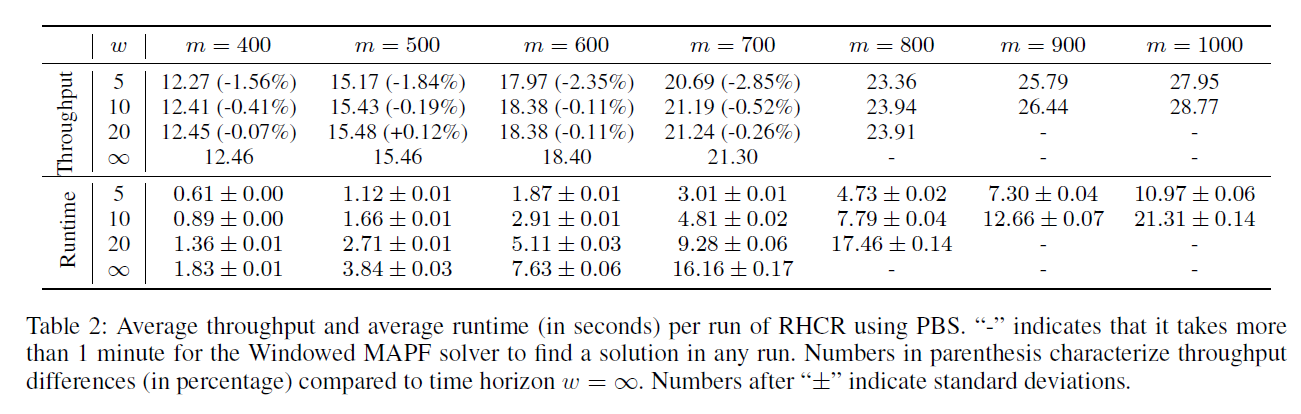
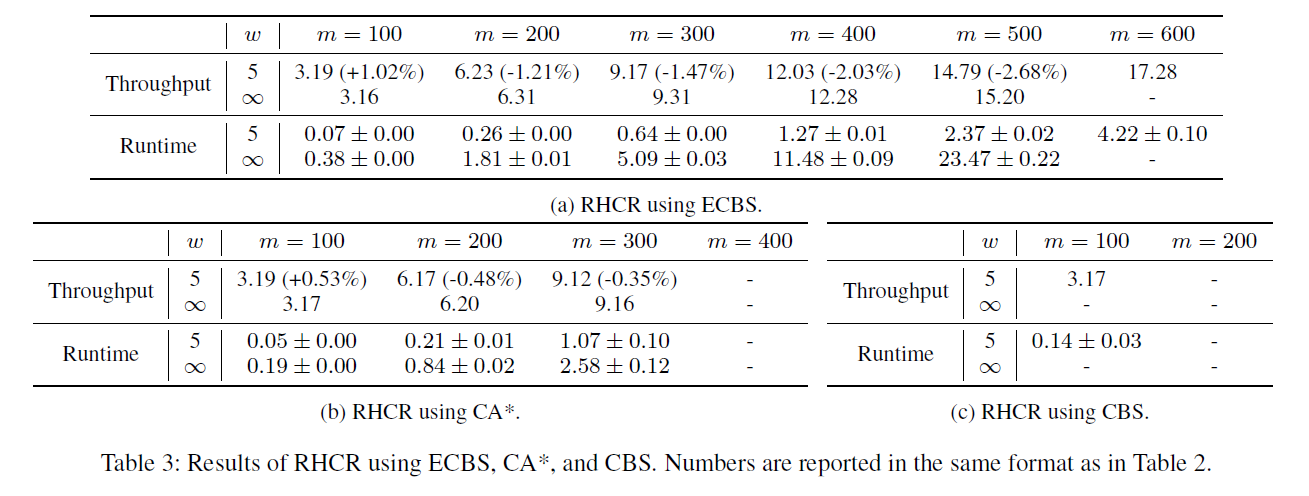
Sorting center map에서는 RHCR을 PBS, CA*, ECBS를 이용했을 때의 성능을 비교했습니다.
w의 크기가 성능에 크게 영향을 주지 않지만 실행시간을 크게 늘리는 것을 확인할 수 있습니다.
- w가 커짐에 따라 "-" 결과가 많아지는데 "-"는 실행 시간이 60초 이상 걸려서 timeout이라는 뜻입니다.
- Table2를 보면 w=∞ 일 때, agent 수가 700까지 가능하지만 w를 줄이면 agent 수를 1000까지 확장 가능합니다.
3. Dynamic Bounded Horizons 실험
논문에서는 Potential Function과 threshold p가 잘 동작하는지 확인하는 실험도 구상했는데요.
w의 초기값을 5라는 낮은 값으로 설정하고, p=60으로 크게 설정하여서 Potential Function으로 w 값이 결정되는 케이스와 w를 고정적으로 설정한 케이스를 비교하는 실험을 진행했습니다.
- Fulfillment warehous map에서 ECBS(suboptimality=1.5)로 60개의 agent를 이용하여 실험을 진행했습니다.
| Throughput | Runtime | |
| Dynamic W(평균 9.97) | 2.10 | 0.35s |
| w=5 | 1.72 | 0.07s |
| w=10 | 2.02 | 0.17s |
Potential Function을 이용하여 W를 찾은 경우가 Throughput이 더 높지만 Runtime이 차이가 많이 나는 것을 확인할 수 있습니다.
4. 리뷰
Potential Function과 threshold p를 설정하는 방법
논문에서는 window size를 런타임에 조절하기 위해서 Potential Function과 threshold p를 제안합니다. 그리고 실험을 통해서 Potential Function으로 인해 성능이 향상되는 것도 보여줍니다.
하지만 적절한 Potential function과 threshold를 어떻게 찾을 수 있는지는 우리의 몫으로 남겨진 것 같습니다. 애초에 RHCR에 Potential function을 더하더라도 completeness가 보장되지 않기 때문인데요.
RHCR을 사용하더라도 주어진 환경에서 성능을 최적화 하기 위해서는 추가적인 도메인 지식이 필요하겠네요...!
환경에 맞춰서 window 크기를 조정하는 방법
논문의 conclusion을 보면 가능한 후속 연구로 환경에 적합한 window 크기를 찾는 것이 있습니다.
MAPF 연구에서 언급되는 주요 환경으로는 Corridor(=좁은 통로)가 있을 것 같습니다.
하나의 로봇만 지나갈 수 있는 좁은 통로거나 한 쪽 끝이 막혀 있는 곳으로 로봇이 몰리면 데드락이 발생하기 쉬워집니다.
그런데! 딱 맞는 연구가 있더라고요!
- SONG, Soohwan; NA, Ki-In; YU, Wonpil. Anytime Lifelong Multi-Agent Pathfinding in Topological Maps. IEEE Access, 2023, 11: 20365-20380.
- 2023년 따끈따끈한 논문입니다!
또한, 작업 수행 시간이 길어서 로봇이 오래 정차해 있는 경우에도 적절히 처리해주지 않으면 데드락이 발생할 수 있습니다.
이런 경우에는 어떻게 해결할 수 있을까요?
일단 SIPP와 Priority가 생각나던데 관련된 연구가 뭐가 있을지 모르겠네요.
Lifelong MAPF 문제에서 Completeness, Optimality
CBS를 공부할 때만 하더라도 MAPF 문제를 풀고 있었고, 알고리즘의 완전성과 최적성이 정말 중요했었는데요.
어느새 Lifelong MAFP라는 비슷하지만 완전히 다른 문제를 공부하면서 알고리즘의 특징들도 많이 달라진 것 같습니다.
대부분의 Lifelong 알고리즘들이 Completeness를 보장하지 않고, 실행 시간에 중점을 두고 있습니다.
Completeness가 보장되지 않는다면 현장은 어떤 환경인지, 로봇이 얼마나 많은지, 작업 방식은 어떤지 등 문제 조건에 따라서 적합한 알고리즘도 달라지고, 정책을 추가하거나 수정하는 등의 조치가 필요해지게 되는 것 같습니다.
이러다보니 "어차피 Completeness를 보장할 수 없다면 딥러닝을 이용해도 괜찮지 않을까?" 라고 생각이 들더라고요.
찾아보니 이미 진행된 연구들이 있더라고요ㅋㅋㅋㅋ
- SARTORETTI, Guillaume, et al. Primal: Pathfinding via reinforcement and imitation multi-agent learning. IEEE Robotics and Automation Letters, 2019, 4.3: 2378-2385.
- DAMANI, Mehul, et al. PRIMAL $ _2 $: Pathfinding via reinforcement and imitation multi-agent learning-lifelong. IEEE Robotics and Automation Letters, 2021, 6.2: 2666-2673.
생각보다 모델은 간단한데 제가 딥러닝, 강화학습 쪽을 잘 모르다보니 많은 인사이트를 얻기는 어렵겠더라고요 ㅜ
RHCR 논문은 어떠셨나요?
이번 논문은 저자가 예시를 많이 적어줘서 이해하는데 큰 도움이 되었던 것 같아요!
- RHCR이라는 개념이 그렇게 어려운 것은 아니라서 설명하는 것에 더 큰 힘을 쏟은 것 같다는 느낌을 받았습니다.
책상 위의 논문 더미가 사라지질 않네요. 딥러닝은 또 언제 공부해야 하려나 ㅋㅋㅋㅋ
공부할 것이 너무 많아서 행복합니다 ㅎㅎㅎㅎㅎㅎㅎㅎ

P.S.
인용수가 논문의 전부는 아니지만 인용수가 높은 논문들은 다르긴 다르네요 ㅋㅋㅋ



