
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- 오블완
- github
- leetcode
- 14일 공부
- 디자인 패턴
- terraform
- Til
- ssh
- DevOps
- amazon ecs
- 생성 패턴
- 경로 계획 알고리즘
- 티스토리챌린지
- Rust
- AWS 비용 절감
- study
- 청첩장 모임
- PostgreSQL
- Go-lang
- docker
- 회고
- 커머스
- 논문 정리
- 실용주의 프로그래머
- AWS
- MAPF
- 구조 패턴
- 토스
- 지표
- Playwright
- Today
- Total
밤 늦게까지 여는 카페
floyd warshall 알고리즘 - 이 정도는 되야 지도를 외웠다고 할 수 있죠! 본문
안녕하세요. 오늘은 floyd warshall 알고리즘을 공부하려고 합니다.
floyd warshall 알고리즘은 모든 노드 간의 최단 경로를 구하는 알고리즘입니다.
dijkstra 혹은 bellman-ford 알고리즘을 여러번 사용하면 되는 거 아니야? 라고 질문하실 수 있지만
floyd warshall 알고리즘을 한번 사용하는 것이 속도가 빠릅니다!
풀어야 하는 문제에 맞춰서 적절한 알고리즘을 사용하는 것이 중요한 것 같습니다 ㅎㅎ
이제 floyd warshall 알고리즘에 대해서 자세히 살펴볼까요?
알고리즘 설명
floyd warshall 알고리즘의 동작 방식에 대해서 살펴보도록 하겠습니다(생각보다 단순합니다!).
1. 모든 노드에서 자기 자신으로 가는 거리는 0으로 초기화합니다.
2. 노드 i에서 노드 j로 가는 경로가 직접 연결되어 있지 않은 경우, 거리를 무한대로 설정합니다.
3. 노드 i에서 노드 j로 가는 경로가 직접 연결되어 있는 경우, 해당 거리로 설정합니다.
4. 모든 노드 k에 대해, 노드 i에서 노드 j로 가는 경로를 노드 k를 거쳐 가는 경로와 비교하여 최소 거리를 업데이트합니다.
진짜 단순하죠?? ㅋㅋㅋ 그래서 예제 코드도 가장 간단합니다 ㅋㅋㅋ
시간 복잡도
floyd warshall 알고리즘의 속도가 더 빠르다고 말씀드렸는데 사실 항상 그런 건 아닙니다!
어떤 상황에서 빠른지 시간복잡도를 이용하여 간단히 설명드리겠습니다.
각 알고리즘 별 시간 복잡도는 다음과 같습니다.
- floyd warshall 알고리즘: O(V^3)
- bellman-ford 알고리즘: O(V^2 * E)
- dijkstra 알고리즘: O(V^2 * E * log V + V^3)
엣지의 개수가 노드의 개수보다 많은 상황에서는 floyd warshall 알고리즘을 사용하는 것이 더 빠르게 되는 것이죠.
dijkstra 알고리즘 시간 복잡도 계산 과정
피보나치 힙을 이용한 dijkstra 알고리즘의 시간복잡도는 O(E * log V + V)입니다.
dijkstra 알고리즘을 이용해서 모든 노드 간의 최단 경로를 구하기 위해서는 V^2 번만큼 알고리즘을 실행해야 합니다.
그러면 시간 복잡도가 O(V^2 * E * log V + V^3) 로 계산됩니다.
bellman-ford 알고리즘 시간 복잡도 계산 과정
bellman-ford 알고리즘의 시간 복잡도는 O(V * E)입니다.
bellman-ford 알고리즘을 이용해서 모든 노드 간의 최단 경로를 구하기 위해서는 V 번만큼 알고리즘을 실행해야 합니다.
그러면 시간 복잡도가 O(V^2 * E)로 계산됩니다.
예제 코드
floyd warshall 알고리즘도 과정이 너무 길어서 그림 예시를 준비하지 못했습니다.
바로 예제 코드를 살펴보도록 하겠습니다!
from dataclasses import dataclass
from typing import List
import pprint
@dataclass
class Node:
id: int
is_visited: bool = False
@dataclass
class Edge:
start_node: Node
end_node: Node
weight: float
def get_weight(self) -> float:
return self.weight
def get_other_node(self, node_id: int) -> Node:
if self.start_node.id == node_id:
return self.end_node
else:
return self.start_node
@dataclass
class Graph:
nodes: dict
adjacent_edges: dict
def get_node(self, node_id: int) -> Node:
return self.nodes[node_id]
def set_node_visited(self, node_id: int):
self.nodes[node_id].is_visited = True
def get_connected_nodes(self, node_id: int) -> List[Node]:
adjacent_edges = self.adjacent_edges.get(node_id, [])
return [edge.get_other_node(node_id) for edge in adjacent_edges]
def get_adjacent_edges(self, node_id: int) -> List[Edge]:
return self.adjacent_edges.get(node_id, [])
def set_edge_weight(self, edge_id: int, weight: float):
self.edges[edge_id].set_weight(weight)
def floyd_warshall(graph: Graph) -> dict:
path = {}
nodes = graph.nodes
for node in nodes.values():
path[node.id] = {}
for other_node in nodes.values():
if node.id != other_node.id:
path[node.id][other_node.id] = float("inf")
else:
path[node.id][other_node.id] = 0
for adjacent_edge in graph.get_adjacent_edges(node.id):
other_node = adjacent_edge.get_other_node(node.id)
path[node.id][other_node.id] = adjacent_edge.get_weight()
for pivot_node in nodes.values():
for start_node in nodes.values():
for end_node in nodes.values():
path[start_node.id][end_node.id] = min(
path[start_node.id][end_node.id],
path[start_node.id][pivot_node.id] + path[pivot_node.id][end_node.id],
)
return path
if __name__ == "__main__":
nodes = {}
for i in range(6):
nodes[i + 1] = Node(id=i + 1)
adjacent_edges = {}
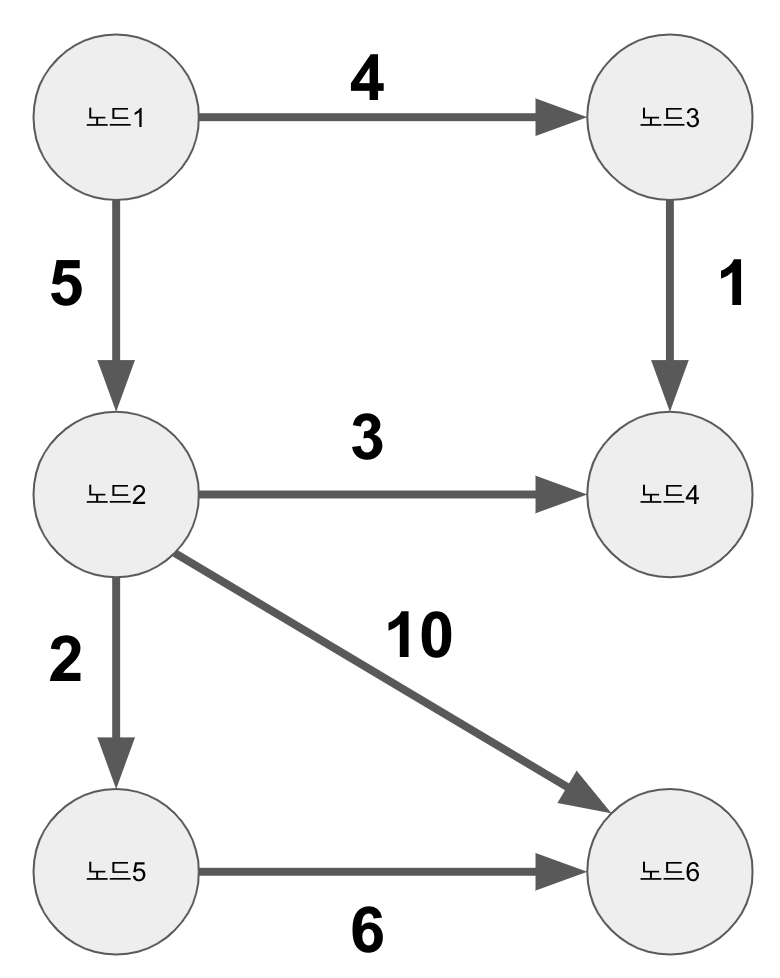
adjacent_edges[1] = [Edge(start_node=nodes[1], end_node=nodes[2], weight=5)]
adjacent_edges[1] += [Edge(start_node=nodes[1], end_node=nodes[3], weight=4)]
adjacent_edges[2] = [Edge(start_node=nodes[2], end_node=nodes[4], weight=3)]
adjacent_edges[2] += [Edge(start_node=nodes[2], end_node=nodes[5], weight=2)]
adjacent_edges[2] += [Edge(start_node=nodes[2], end_node=nodes[6], weight=10)]
adjacent_edges[3] = [Edge(start_node=nodes[3], end_node=nodes[4], weight=1)]
adjacent_edges[5] = [Edge(start_node=nodes[5], end_node=nodes[6], weight=6)]
graph = Graph(nodes=nodes, adjacent_edges=adjacent_edges)
pprint.pprint(floyd_warshall(graph=graph))
floyd warshall 알고리즘의 핵심은 다음 코드라고 생각합니다.
path[start_node.id][end_node.id] = min(
path[start_node.id][end_node.id],
path[start_node.id][pivot_node.id] + path[pivot_node.id][end_node.id]
)
다른 노드로 가는 경로에 대해서 모든 경우를 다 상정하기 때문에 최단 경로를 찾을 수 있는 것이죠.
그리고 코드도 간단하지 않나요? ㅎㅎㅎ
이제 예시 그래프와 함께 floyd warshall 알고리즘을 활용해볼까요?
예시 그래프
실행 결과
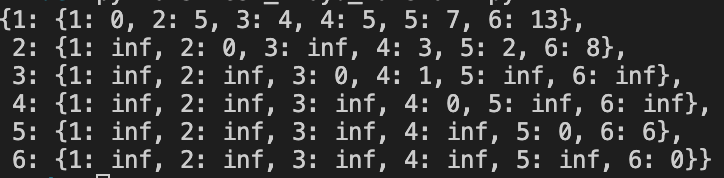
- 키가 시작 노드이고, 값은 시작 노드에서 각 노드로 가는 경로의 길이를 의미합니다.
- inf는 시작 노드에서 목적 노드로 가는 경로가 없다는 뜻입니다.
이제 탐색 알고리즘은 B* 알고리즘과 PEA* 알고리즘이 남았네요!
끝나면 다시 다중 에이전트 경로 계획 부분을 공부하게 되는데 벌써부터 떨리네용 ㄷㄷ;;;
더 공부하고 싶으신 내용이나 부족한 부분 알려주시면 보완하도록 하겠습니다.
감사합니다 👍
'스터디 > Path Finding' 카테고리의 다른 글
| RBFS 알고리즘 - A* 알고리즘이 메모리를 너무 많이 사용할 때는 어떻게 해야 할까요? (0) | 2023.04.08 |
|---|---|
| [CBS] Optimality & Completeness 정리 (0) | 2023.03.26 |
| bellman ford 알고리즘 - dijkstra 알고리즘 다음은 bellman ford죠! (2) | 2023.02.18 |
| dijkstra 알고리즘 - 스타벅스로 가는 가장 짧은 길이 어떻게 되죠? (0) | 2023.01.31 |
| DFS 알고리즘 - 하나를 깊게 파는 것도 중요하다구요! (0) | 2023.01.21 |


